
Unable to receive large messages
I'm running into an odd problem. I'm using ROS2 Galactic inside of docker images, one of which is running on my laptop, and another running on a Husky robot. In case network topology matters, here is a diagram of the setup: 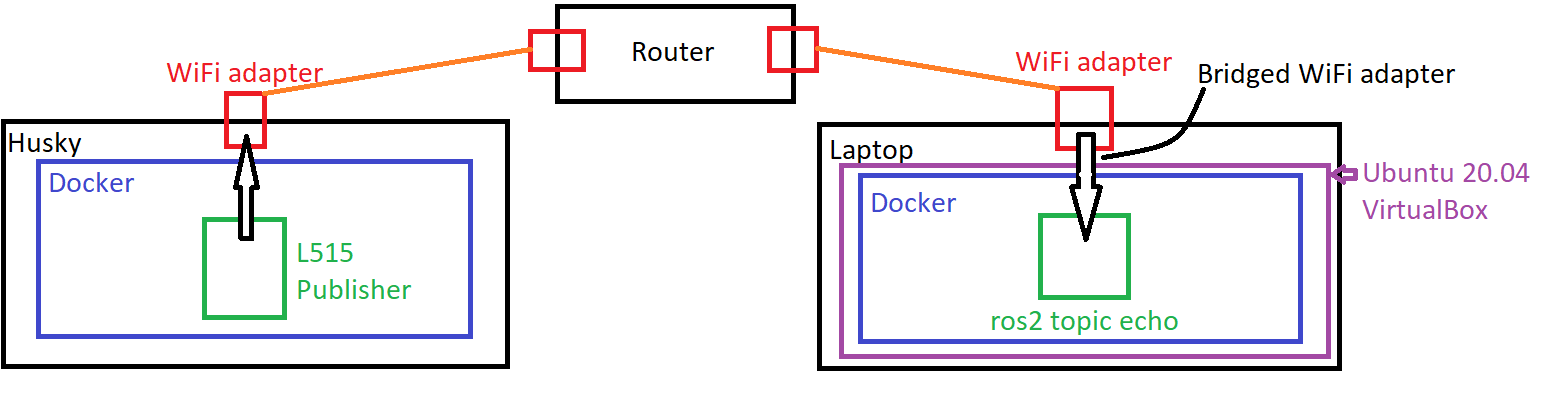 The robot is at 192.168.131.1, and my laptop is 192.168.131.116. Both images are run with
The robot is at 192.168.131.1, and my laptop is 192.168.131.116. Both images are run with --net host --privileged.
If I run a simple talker in the Husky's docker image and echo the topic on my laptop docker image, I receive the data just fine. All data can be delivered in a single UDP packet, and so no reassembly needs to take place on either the robot or my laptop.
However, when I send larger messages over topics, I can no longer receive the data. I have tested this with VLP-16 LIDAR PC2 data, as well as L515 Realsense camera data. I again captured packets on both the robot and my laptop, both still under the same IP. I can echo these topics fine locally on the robot's docker image, but not from my laptop's docker image.
DISCLAIMER: I'm not a network expert, so the analysis below could be wrong (and please tell me if it is).
Here is a snippet of the capture from the robot: 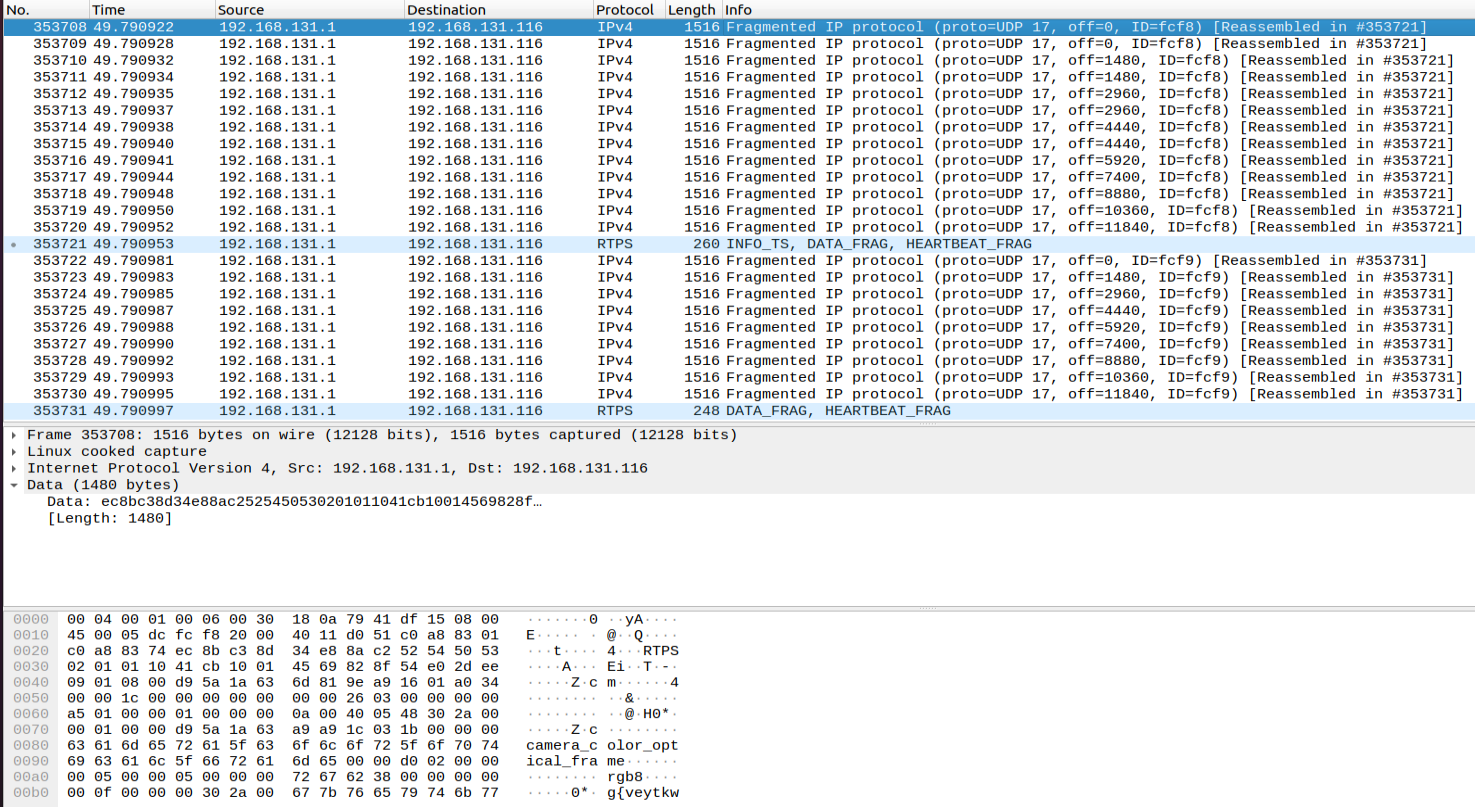 Packet #s 353708-353720 are fragments of the image. These are reassembled in packet #353721, and the top of the raw packet bytes at the bottom show the
Packet #s 353708-353720 are fragments of the image. These are reassembled in packet #353721, and the top of the raw packet bytes at the bottom show the camera_color_optical_frame and rgb8 metadata.
Here is a snippet of the received data on my laptop: 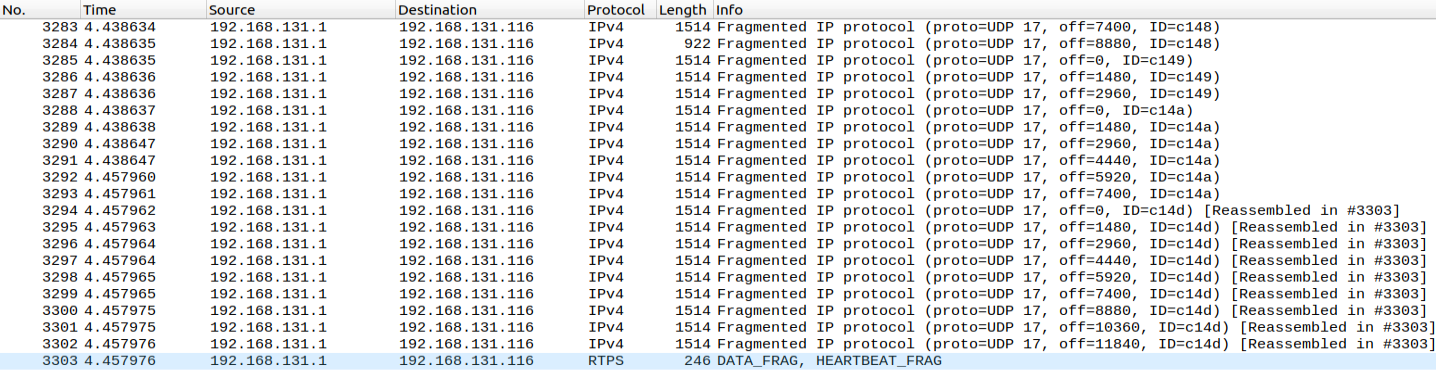 I believe that packets 3285-3302 should all be reassembled in 3303, but only 3294-3302 are reassembled. Here is the data for packet 3285:
I believe that packets 3285-3302 should all be reassembled in 3303, but only 3294-3302 are reassembled. Here is the data for packet 3285: 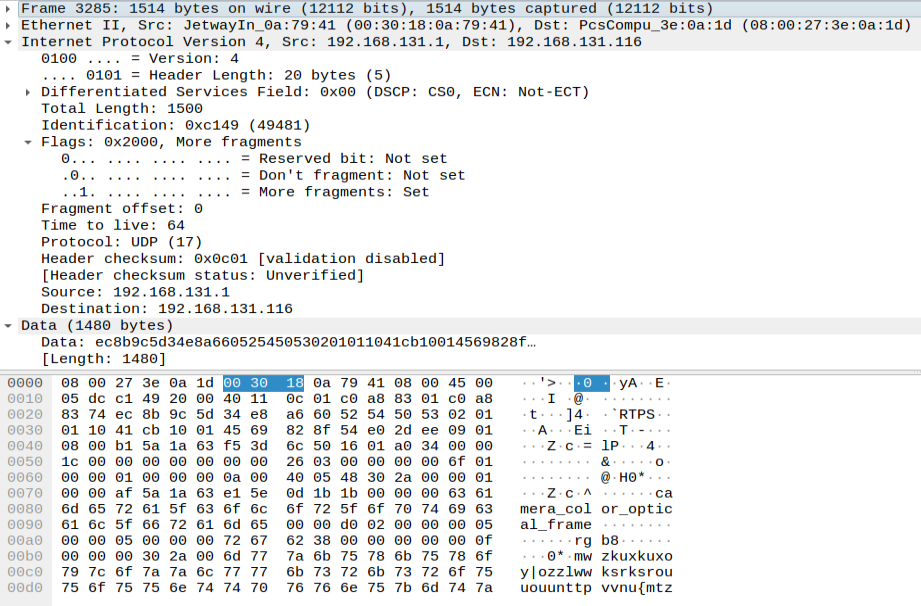 This includes the aforementioned metadata
This includes the aforementioned metadata camera_color_optical_frame and rgb8, but it never ends up in a reassembled packet.
(note that the above packet captures are not the same same message; I don't have synced clocks between robot and laptop. I hope it illustrates the point about packet reassembly, but I can update with matching sends and receives if that helps.)
I have tried:
Swapping DDS implementations from CycloneDDS to Fast RTPS
Following all debugging/tuning recommendations at https://docs.ros.org/en/rolling/How-T...
Changing publisher QOS to "Best Effort"
Tried other large message publishers (namely VLP-16 pointclouds)
to no avail. Furthermore, when subscribing to VLP-16 pointcloud topics, all network connections I have to the robot cease until ~30s after I kill the subscriber on my laptop. I believe that the issue is either a core networking driver problem, or a misconfiguration/bug of Cyclone DDS.
What should I do to debug further, and/or resolve the problem? Thank you!

That is weird. What happens if you publish only a single large message? I assume the "L515" publisher is publishing at some relatively fast frequency (10-30Hz)? Maybe you could record a bag file and play it back in its place and step through it with the cli or rqt_bag? Or you could write a python script to run on the husky which subscribes to the topic, republishes only the first message on a new topic, then just idles, and then you can echo the new topic on your laptop (effectively creating a throttled topic). I'm wondering if the issue is related to resending packets, but you said best effort also fails... It's definitely strange.
Also, this is similar to how things failed with the IP fragments issue described in https://docs.ros.org/en/rolling/How-T... (which you said you looked at). Can you confirm that these settings are changed on both ends? I don't know how docker might interact with this... but my first guess is that it shouldn't be an issue.