
Lag in recieving messages to a subscriber
I am using foxy with cyclone dds and all the nodes are running in the same host.
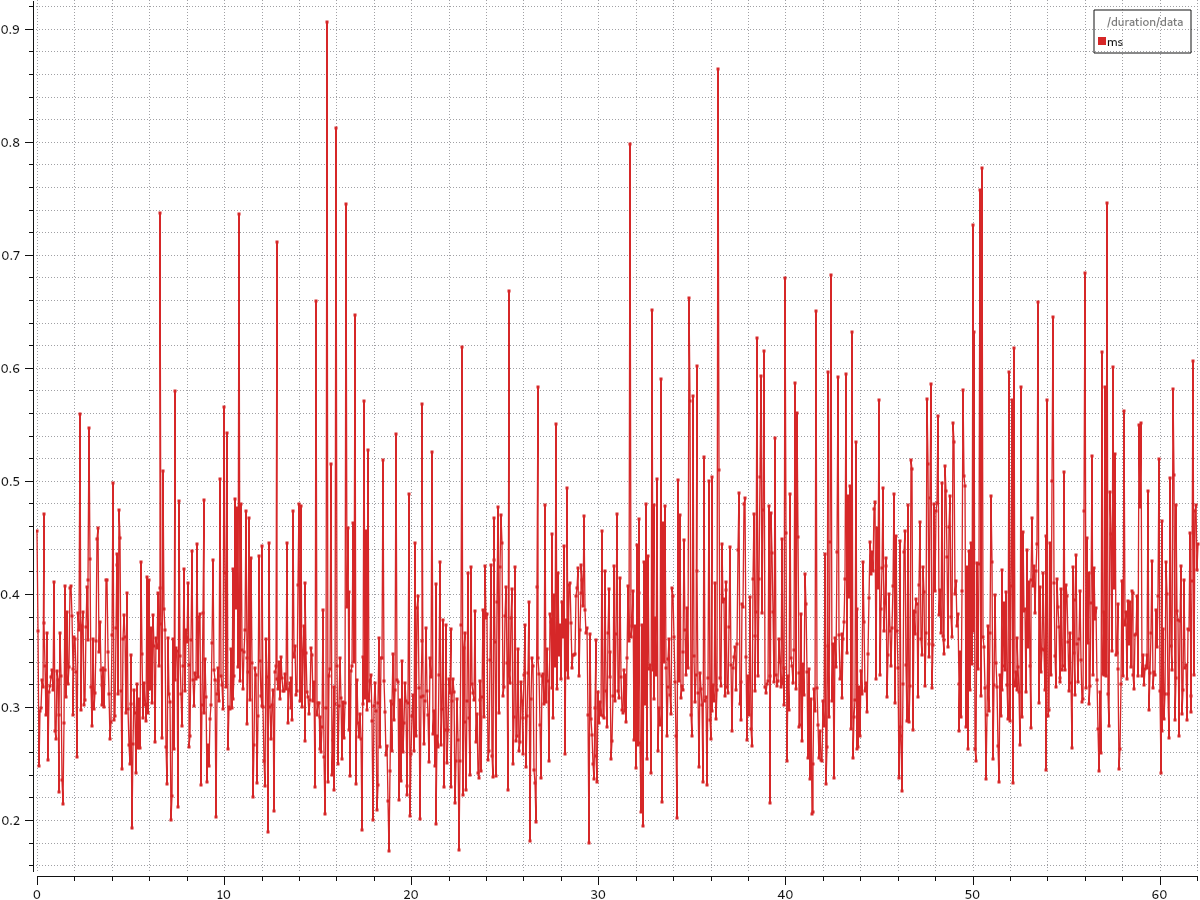
I created a simple publisher and subscriber and measured time for the message to reach from the publisher to subscriber. On an average, it took around 0.35ms for a geometry_msgs/Twist data for a subscriber to receive the message published by the publisher.
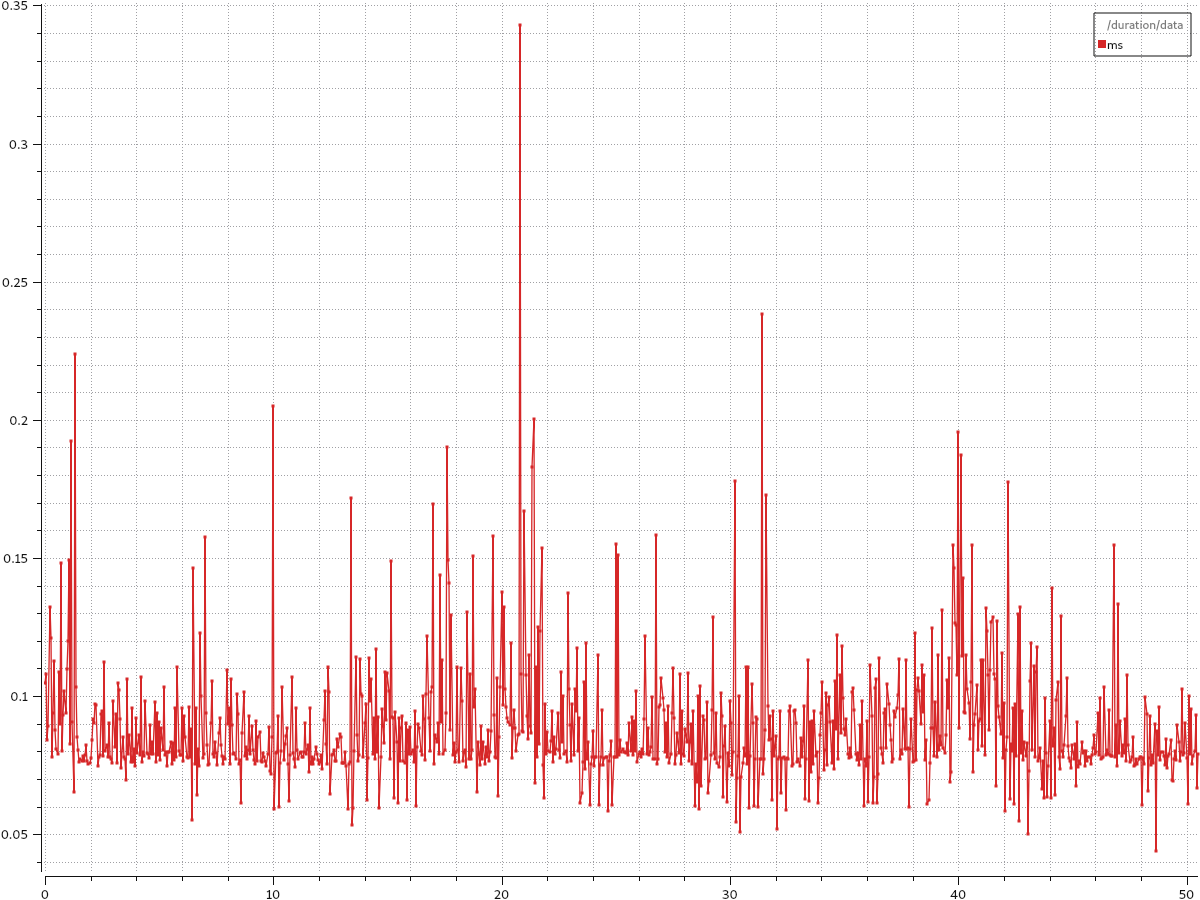
I tried to use intra process communication to see how much improvement i can get from that. It gave around 0.09ms for the message to be passed to the subscriber.
Is there any way I can speed the message exchange as it seems weird that simple message passing takes this much time when the controller runs at a much faster speed.
I have tried the intra process according to this. I tried fastdds and also different qos profile but I couldn't find much difference in speed.
I could find that intraprocess is not available for service and it also takes around 1 ms for message passing. Is there any way I can improve the speed.
Plots:

Can you describe what you are trying to do where you consider 0.35 milliseconds is too slow? Maybe ros is not the correct middleware.
May be I shouldn't have... But however many of my work is now in ros2, it would be difficult to move away from ros now.. Do you know how i can speed the transmission further or is it the maximum you can have ?
Is 0.35ms correct? Is it not 0.35 seconds? That's a factor 1000. 0.35 milliseconds is 350 microseconds, or 350 millionth of a second ..
Same for 0.09ms. That's only 90 microseconds.
@fayyaz: could you describe your setup a little? 90 microseconds isn't all that much, but there are of course robots/processes for which it is too much. Especially if there are multiple intermediary pub-sub steps.
The plot is in milliseconds. So it is 0.35 ms and 0.09ms.
As there are multiple publisher and subscribers, the delay adds on and it starts to amount to a notable delay. Let's say the encoder data from wheels, imu and other sensors and a node of ekf to fuse them and then passing the pose to the navigation controller, the delay of 0.35ms slowly starts to become relevant eventhough we are running all the nodes in the same host.
I doubt if there might be something which i might have missed to make it faster further and hence i posted the question.
Also in case of intraprocess, I can have that only between two nodes and if I subscribe to the topic in another node, It rolls back to the same nature similar to interprocess.
Also as there is no intraprocess defined for services, I ...(more)
There are quite some organisations/people/companies using ROS 2 for the kinds of use-cases you describe, so it does surprise me you identify communication delays as problematic. I'm not dismissing your experiences though. It's very likely you have additional requirements and/or constraints which exacerbate this problem.
Typical mobile robots I know don't use ROS to transport encoder ticks or close the loop at that low of a level in the control hierarchy. An interface which publishes
JointStates and acceptsgeometry_msgs/Twistis often seen. The embedded controller of the mobile base then takes care of the rest.Hosting all of your nodes inside a single container, using intra-process communication can definitely help, but you'd still need to make sure to subscribe to the topics which are less sensitive to pub-sub delays (as you've noticed yourself).
I'm not sure how services are ...(more)
But to clarify: I can't give you a direct answer to:
Perhaps someone with more experience using ROS for these kinds of low-level tasks could contribute something.
One last though: if using vanilla ROS 2 is not necessarily a requirement, you could see whether Micro-ROS could help here. That would still allow you to use a ROS 2 interface to your low-level control, while dealing with the low-level control itself in a more traditional embedded way.
Thank you for the clarification. It's just that the controller was able to solve an optimization problem in less than a millisecond, but it takes around the same time to just send the optimized solution to a different node. May be running in a realtime kernel might improve the communication faster i guess. Thanks a lot for answering the query quickly.
Using a middleware to communicate between individual processes is always going to incur a cost.
Intra-process (ie: shared memory) communication can mitigate this somewhat, but it's never going to be as fast as exchanging pointers between functions in a single process. That's just not how this works.
Note that this is not unique to ROS (1 or 2): it's a common characteristic of networking and the way processes work.